Avro, Kafka and the Schema Registry: Clearing Things Up
Demystifying Avro and the secret schema registry protocol
From a bird’s-eye view, Avro is a binary serialization format just like many others: structured data can be serialized into a compact binary format to speed up the transport of data and to save storage space. However, when you take a closer look at Avro, fundamental differences to other established serialization schemes like Protobuf or Thrift become evident. In practice, those differences manifest themselves in a comparatively high compression ratio on the one hand, but an increase in complexity on the other.
Especially when employed in a distributed system, where serialized data is pushed over the wire, dealing with Avro becomes tricky. In particular, the concept of schema registries seems to be a common cause of confusion.
Everybody who has worked with an Avro/Kafka setup has probably at some point wondered:
- When in the application’s lifecycle should a schema be registered?
- When is a schema pulled from the schema registry?
- When does the compatibility check take place?
- Why do I even need to pull a schema when the schema is already baked into the application?
- Why did my application crash with a deserialization exception again?
- Can we use JSON, please?
This blog post may not have an answer to all of these questions but it’s a good starting point if you want to find out what goes on under the covers.
What’s the point?
Why are schema registries a thing? And why do you hear the term mostly in the context of Avro and not so much in the context of, say, Protobuf? In order to answer this we first have to understand how Avro is different from other protocols. One of the key differences is that binary protocols such as Protobuf and Thrift rely on tags as means to match byte sequences to fields, whereas in Avro, such a concept does not exist.
Tags vs. no tags
Tags are a way of mapping each field of a schema to a unique number, an ID. Within a serialized record, we can refer to a field by its ID and not say, by it’s name as it is the case for JSON. The result is that the serialized byte sequence is a lot more concise (compare a single integer to variable-length string). When the deserializer traverses a binary record and encounters a tag then it knows that the byte sequence that follows belongs to the field associated with that tag.
Here’s an example…
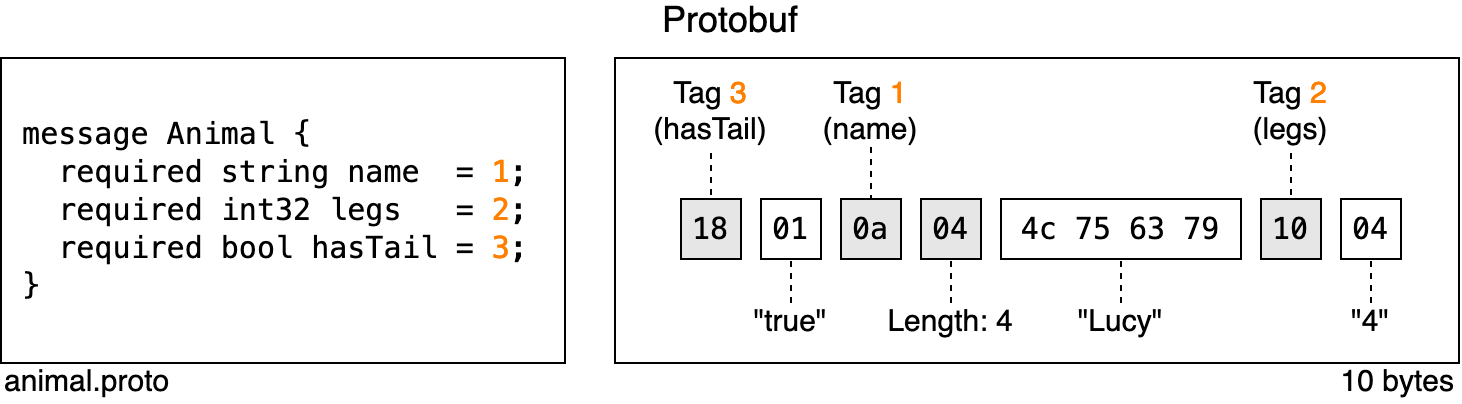
On the left-hand side, you can see a Protobuf schema for the type “Animal” with three tags: the tags 1, 2 and 3 correspond to the fields “name”, “legs” and “hasTail”, respectively. On the right hand side, you can see a record which was serialized with that schema. We easily find that the animal in question is named “Lucy”, has four legs and a tail. You don’t have to understand every detail of the binary output, just know that the tags (marked in orange) tell the deserializer which bytes correspond to which field. This is important because the fields in the byte sequence are not in the same order as they were defined in the schema.
A disadvantage of tags is that they take up quite a bit of space (in the case of Protobuf it’s one byte per tag). In the image above, all bytes related to “meta data” are marked in grey, the remaining white boxes are the actual payload. You can see that the ratio between meta data (overhead) and payload data is not ideal. Can’t we reduce the number of grey boxes, e.g. by getting rid of tags? With Avro, we can. Avro does not rely on tags to identify fields. Instead, in the serialized byte sequence, all fields are appended back to back.
Here’s is the Avro equivalent of the Lucy example:
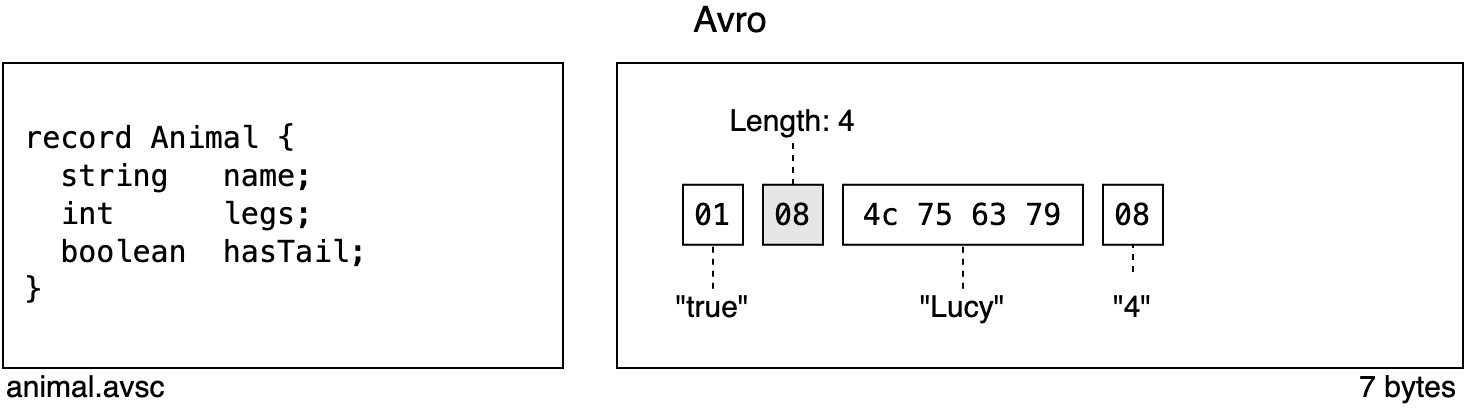
Again, on the left hand side we see the schema, the reader’s schema to be precise. On the right hand side, the serialized record.
The first thing you might notice is that the record is quite a bit more compact. It takes up 30% less space than the Protobuf equivalent: 7 bytes vs. 10 bytes. The field values are marshaled byte-after-byte and there’s a lot less meta data within the record (fewer grey boxes).
Now you might be wondering: how does the deserializer know which byte sequence belongs to which field when there is no way of identifying the fields? How do we know that Lucy has four legs and not just one? Just by looking at the reader’s schema we cannot possibly know. In order to find out we need to look at the schema which the writer used when serializing the record. With both schemas side-by-side, we can make a comparison and find out the correct order of the fields.

The order is all mixed up. According to the writer, hasTail should be at position one whereas according to the reader, it should be at position three, etc. But this is not a problem since the reader now has both schemas, they can reorder the fields and deserialize the record.
This approach, however, poses another problem: How does a reader know the writer’s schema? Here’s where the schema registry comes in.
Schema registry to the rescue
As the name suggests, a schema registry is a store for schemas. It provides an interface that allows you to retrieve and register schemas and check each of the schemas for compatibility. Effectively, it is nothing more than a CRUD application with a RESTful API and a persistent storage for schema definitions. Within the schema registry, each schema is assigned a unique ID. The reader can simply query the schema registry for the writer’s schema ID and retrieve the schema definition.
Now, we still haven’t clarified how the writer tells the reader which schema was used for serialization. There are several ways to do this. In the context of Kafka, there is one established method which relies on the convention that the writer prepends each serialized record with its respective schema ID before it is sent over the wire. The reader can then parse the first few bytes to find out the schema ID and ask the schema registry for the schema definition. Only then, the reader can determine schema compatibility, reorder the schema’s fields and start deserializing.
I know this might be a bit confusing (at least it was for me) so let’s have a look at an example.
The protocol
In this example scenario, we’ll look at a publisher who wants to write the Avro-serialized message “Foo” to the topic “my_topic” and a subscriber who wants to read that record.
The writer’s side
Let’s first have a look at the left half of the image and take the writer’s perspective.
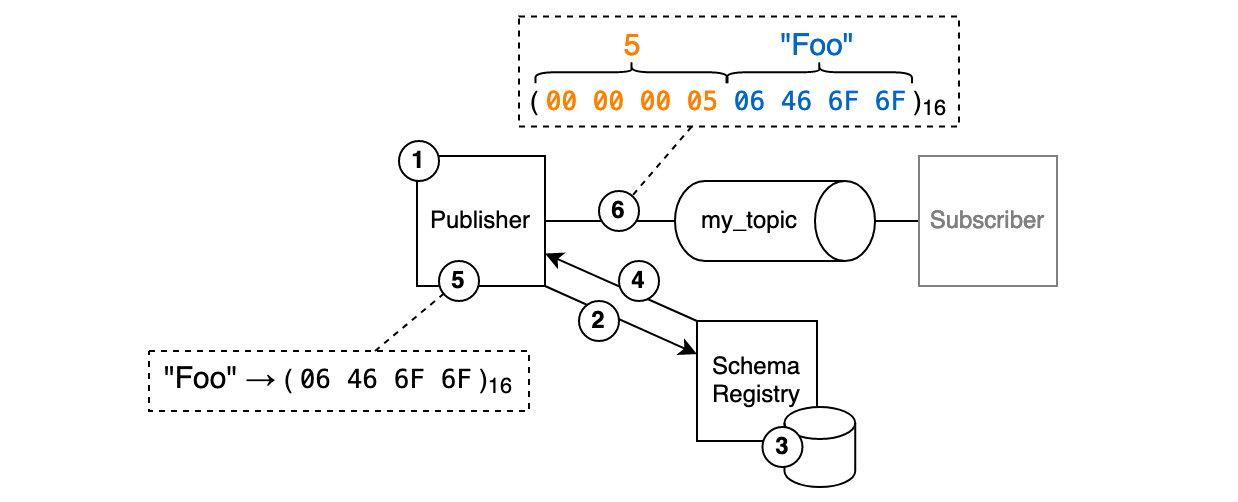
- So we want to write the message “Foo” to the topic “my_topic”. While developing the application, we already determined the schema that we want to use. So technically, we could already serialize the record and publish it. Except, we can’t. Remember: With Avro, we need to signal which schema was used for serialization so that readers can check for compatibility and deserialize. In order to do this, we need the schema’s unique ID. How do we know the correct schema ID? Only the schema registry knows, so let’s ask it.
- We ask the schema registry: “Hey, I want to publish a record to “my_topic” using this particular schema. Is that alright, and if so could you tell me which schema ID to use?”. We do this by calling the API’s registration endpoint. The endpoint expects an Avro schema in the request body. We’re going to put the schema we planned to use inside of it.
- The schema registry receives the request and looks up the schema in its persistent storage (a log-compacted topic named “_schemas”). If no schema is yet registered for the topic (what I refer to as “topic” is actually “subject” in schema registry terms) then the schema is registered and persisted.
- The schema registry compares the schema that it just looked up with the schema that we POSTed. If the schemas are incompatible according to Avro’s schema compatibility rules, a client error (409) is returned to us. But in this example we’re good, the schemas are compatible and the schema ID is returned. Let’s assume that the ID is “5”.
- Great, so we have green light to use our schema for serialization. We serialize the record and find its binary repesentation is “
06 46 6F 6F”. - Now we can prepend the message with the schema ID and publish the record. Off we go!
The reader’s side
Now let’s look at the other half of the image and slip into the role of the consumer.
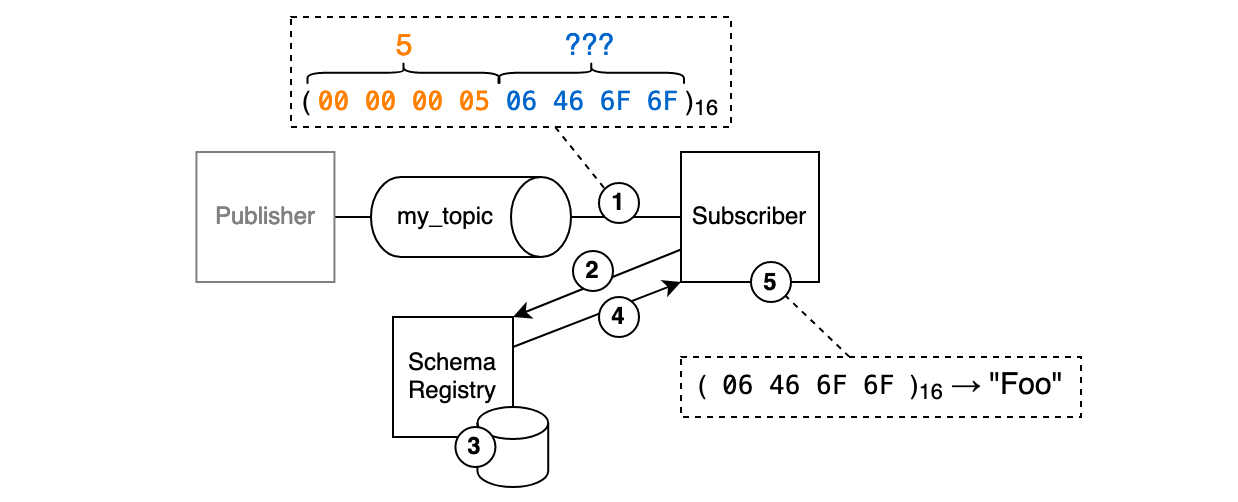
- As a consumer we’re notified about a new record in the “my_topic” topic that the writer previously published to. How do we deserialize the record? We already know which schema to use for deserialization: while writing the application we defined that “for this particular topic we use that particular schema”. But why can’t we just use our own schema and be done with it? The answer is that, again, Avro needs both the writer and the reader schema in order to identify which bytes correspond to which field and to determine whether the schemas are compatible. So we need to retrieve the writer’s schema from the schema registry. We look at the first few bytes of the message and discover that the writer used the schema ID “5”.
- We ask the schema registry which schema is associated with schema “5” by calling the corresponding API endpoint.
- Again, a lookup in the persistent store is made.
- The endpoint returns the schema definition associated with schema ID 5.
- We compare the returned schema with the schema that we planned to use. By looking at the two schemas side-by-side we can identify each field and also determine whether the schemas are compatible. If everything is ok we can finally deserialize the record and read the original message.
Note: It is worth noting that we don’t have to perform the schema lookup for every incoming and outgoing record. The clients can hold the ID-schema-mapping in an in-memory cache and thus skip steps 2 to 4.
There you go, that’s the whole secret!
Conclusion
We’ve seen that Avro is an extraordinarily compact serialization format. As opposed to Protobuf and Thrift, it doesn’t need tags to identify fields in the serialized byte sequence. Much rather, it relies on the fact that a reader needs to know the writer’s schema in addition to its own schema. So the question arises where a reader should get the writer’s schema from. When working with local files, this is not an issue at all since you can simply prepend the file with the schema and then fill the file back-to-back with serialized records - schema and data are always kept together. However, when readers and writers make up a distributed system, things become complicated as schema information needs to be exchanged over the network.
Confluent’s solution for the Kafka world is a protocol which took me a while to fully grok. The idea of the protocol is to prepend each record that is sent out with the writer’s schema ID so that the reader can retrieve the writer’s schema from a central REST API, the schema registry. This imposes quite a bit of complexity on the system as suddently, schemas need to traverse the network and clients need to be enabled to talk to yet another service. Since Confluent’s client libraries take care of all the nitty-gritty details from retrieving the schemas to checking compatibility to (de)serializing records, it is not always obvious to the users what is happening under the covers. Not understanding those details will inevitably come back to bite you and you will find yourself pulling your hairs out debugging serialization problems sooner or later. I hope this post made things more clear for you!