Stream Your Database into Kafka with Debezium
An introduction and experience report on Debezium, a tool for log-based Change-Data-Capture
Debezium is a log-based Change-Data-Capture (CDC) tool: It detects changes within databases and propagates them to Kafka. In the first half of this article, you will learn what Debezium is good for and how it works. The second half consists of an experience report in which I describe the joys and pains of running Debezium in production.
This article intended for architects or (data) engineers who want to learn about a great ETL tool to add to their tool belt as well as teams who are currently on the fence about introducing Debezium to their setup.
But first…
Why?
There’s a number of reasons why you would want to ingest your database’s contents into a publish-subscribe system. For example…
- ETL (Extract-Transform-Load): You want to aggregate all data in a data warehouse for analytics purposes and simply need all your data to go from A to B
- Migrations: You want to replace a legacy system with a new one and want to ingest live data into the new system while the old one keeps running
- Streaming: You want to do stream processing on newly inserted data via Apache Spark, Flink, Kafka Streams, what have you
- Or, you simply want to expose data to multiple clients and don’t want to give all of them read access to the database
- etc.
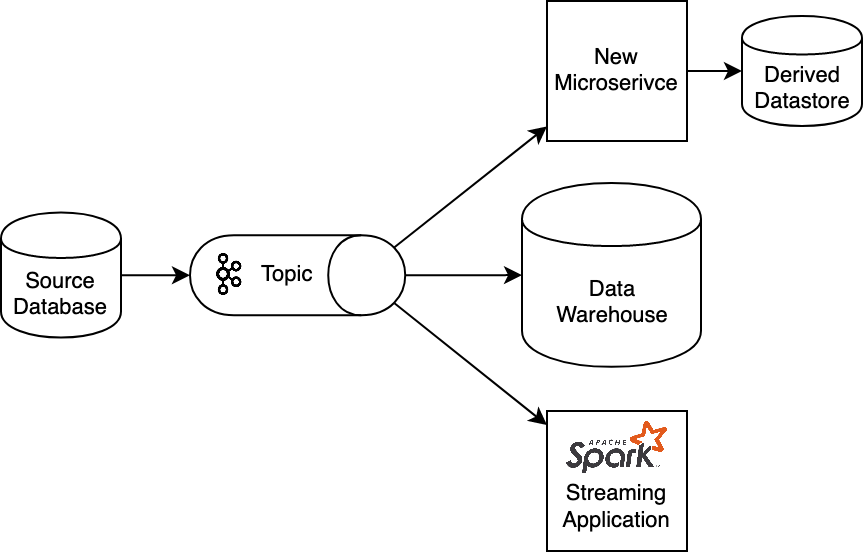
The reasons are manifold. When thinking about how to go about this, most people would naturally come up with two approaches: Dual Writes and SQL polling.
- Dual writes is probably the most primitive approach you could think of. It goes like this: whenever your code writes a record to the database it sends an event to Kafka at the same time. It’s simple right? But it comes with a big disadvantage: How do you ensure consistency between the database and the topic? What if the event is part of a longer transaction that is later rolled back? Sure there are ways to ensure consistency on a code level but you have to be REALLY careful and chances are you or someone in the team will screw up the logic sooner or later.
- With the SQL polling approach you would set up a separate process that runs the same query against the database regular intervals and then publishes an event to Kafka. This approach is only slightly better than the previous one in terms of consistency. There are many questions that require careful consideration, like “how to detect deletions?”, “what is the ideal polling frequency? How much delay am I willing to tolerate?”, etc. Not to mention the increased load you put on the database.
As you can see both approaches are not ideal. Especially when consistency is a concern you probably wouldn’t want to pick either. But can we do better? Of course we can, otherwise you wouldn’t be reading this article 😉 I’ll introduce you to a third approach: Debezium.
What is Debezium?
Imagine this: every time you insert, update or delete a record in your database an event holding information about the change is immediately emitted. This process happens automatically: not a single line of code needs to be written on your part, almost as if it was a feature of the database itself. Even better: it is ensured that every single change is captured; no updates are missed. In other words, it is guaranteed that database and Kafka are eventually consistent. “What is this sorcery?” you might ask. The answer is a process called “log-based Change Data Capture” (CDC). Have a look at the following image.
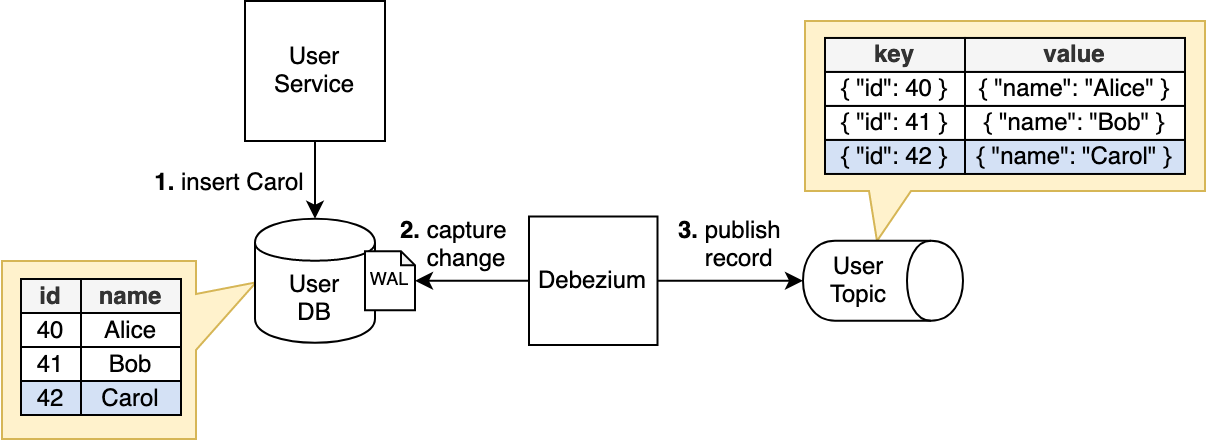
Let’s consider this ordinary CRUD application (“User Service”) that stores user data in an SQL database. Our goal is to propagate the user data via a Kafka topic (“Users Topic”) to other components. Furthermore, a Debezium instance is running. Debezium can be deployed either as a standalone, self-contained process (as we did in this example) or as a Java library that can be included into an existing application.
Now, let’s walk through what happens when the application inserts a user into the database:
- In the first step, the application writes the new user (named “Carol”, marked in blue) via ordinary
INSERTstatement into the the database. An important detail here is that under the hood, databases typically don’t write the data directly “into the table”. Instead, they first append the change to a transaction log file called “Write-Ahead Log” (WAL). In a way, the WAL serves as the single source of truth for everything that’s happening inside the database. An operation that’s not logged in the WAL never officially happened, as far as the database is concerned. Only after the WAL is flushed to disk, we can safely say that the data is “persisted”. - Debezium continuously scans the WAL and as soon as the record is inserted, the associated change is picked up.
- Debezium can then process the insertion. It creates a Kafka record from the inserted row. More precisely, a key-value pair is created (the table’s primary key is used as message key by default) and the row is optionally transformed according to some rules that you can specify. Finally, the record is serialized, either as JSON or Avro and then published to Kafka.
The change event “Carol was added” can now be picked up by whoever subscribes to the users topic. Yay!
It is important to note that the application is entirely oblivious to the fact that there is a Debezium instance or even a Kafka cluster running. From the perspective of the user service, it inserts a row into a database and that’s it. No line of Kafka-specific code was added.
What’s good about it?
In one of our projects, we’re running Debezium in production and while the experience has not been the smoothest one (see next section) there are many good things to be said about it. Here’s what we liked in particular.
- It ensures consistency with the database. Since Debezium relies on the database’s transaction log to capture changes, eventual consistency is given. Debezium replays the WAL in the same way a read replica or a database backup does. In fact, you might even go as far as to say that the resulting topic is a read replica of the database table.
- It handles failures gracefully. Debezium remembers which entries of the WAL it has already processed and persists the read offset in Kafka. If Debezium fails, e.g. because the network connection is lost or because the process crashed, it will continue exactly where it left off. In other words, at-least-once delivery semantics are achieved. So you can rest assured that you miss no changes during downtime.
- It is fast. As the name suggests, records are written to the WAL before they are written to the actual database. Debezium picks up changes from the WAL immediately and as a result, changes are propagated as they occur. This is in stark contrast to the polling approach where a certain latency is unavoidable.
- It is surprisingly flexible. You typically don’t want to expose a table 1-to-1 in a topic. For example, if you don’t want the password column of the user table to be exposed you can simply blacklist it. If you want to have more detailed change log events containing the “before” and “after” of the record, sure you can do that. Maybe you don’t want to emit “delete” events - no worries at all. Debezium provides plenty ways to transform the events before they are sent out.
- It is well documented. One of the reasons that ultimately convinced us to use Debezium is its extensive documentation. You can be sure that the docs provide an answer to any question you might have. And when in doubt, check the project’s gitter. In our experience, the people there are very helpful and respond quite fast.
The pitfalls
In practice, Debezium works nicely and it does what it’s supposed to do reliably. However, there are a few things that we wish we had known or considered before we started using it.
You might be exposing your database schema
When you’re starting off with Debezium it might be tempting to leave the default settings unchanged and simply expose your existing tables as-is to Kafka. However, this is a bad idea for the simple reason that you’re effectively exposing your database schema to the outside world. Why is this bad? Once you start pushing records to your downstream consumers they will expect that the message format to not change anytime soon. The problem is that now your message format is directly tied to your database schema and we all know that database schemas need to be evolved more often than you think. Now every time you want to change the database schema you need to deal with a (possibly breaking) change of your API. Your nicely decoupled architecture isn’t so decoupled anymore.
The issue becomes worse when you’re using Avro serialization. Debezium infers the Avro schema from the database schema. Since both schemas are now effectively the same thing you’re now imposing Avro’s schema compatibility rules onto your database schema. In pracice this means that you have to be really cautious when adding or deleting columns, otherwise you might break compatibility with the consumers.
With this in mind it becomes clear that you need to establish some sort of alternative read model to feed into your clients. How do you do that in SQL? Views! So let’s use SQL views then! …Or maybe not because…
(Materialized) views are not supported
If you thought you could simply create an SQL view and let Debezium publish that you are mistaken. Debezium simply doesn’t support any kind of views, be it materialized or not. What you should do instead is to make use of the outbox pattern. The idea of the outbox pattern is that you maintain a separate table specifically for the purpose of holding outgoing events. Only this table should be monitored by Debezium. The trick is that this table needs to be updated transactionally, e.g. via database triggers. In the user example from above you would need to create an create/update/delete trigger on the users table and let that trigger write update events the outbox table. Thankfully, Debezium provides means to streamline this but nonetheless, this makes matters quite a bit more complex.
Setup could be easier
When you’re used to building applications for the cloud you might have certain expectations of how a service ought be provisioned. For example, you might expect applications to be configurable via environment variables. I was mildly shocked to find out that the only officially supported way to provision Debezium is to POST a config file to a REST API of the running Debezium instance. The config is then persisted in a log compacted Kafka topic which needs to be cleaned up manually after Debezium is torn down (BTW, this is not the fault of Debezium itself but rather the Kafka Connect framework that Debezium is built upon). This behavior contradicts the idea of immutable infrastructures and makes automated deployments rather awkward. If you’re like me and prefer the environment variable way of configuring applications, feel free to use this custom Debezium Docker image that I created to alleviate our deployment pains.
Dealing with joins
When you have a relational database it’s not a far stretch to assume that your schema has relations. The thing is though that Debezium works on a table-level: it only considers tables in isolation and as a result of that, relationships are not considered. If you absolutely cannot do without joins and you don’t want to deal with outbox tables you have to swallow the bitter pill and make the downstream clients join the Kafka topics themselves. Depending on your schema this might be viable but for us it was not. Resolving a 1:10000 relationship via Kafka Streams turned out to perform not too well. We ended up having to de-normalize the schema instead.
Workarounds are necessary for AWS RDS PostgreSQL
Although Debezium supports RDS out of the box (some config changes are required but they are well documented) it doesn’t run as smoothly on RDS PostgreSQL as we had hoped. After rolling out Debezium on our staging environment we soon found that our database was steadily filling up the disk even though there was barely any data in the database and no writes happening at all. Even more curious was the fact that as soon as we started inserting sample data some of the storage would be freed again. After a bit of digging we found a blog post explaining the cause of the issue (which btw. lies in AWS, not in Debezium). If you’re interested in the details I encourage you to check out the blog post but to save you some time I’ll skip right to the “solution”: the workaround we ended up implementing involved, and I kid you not, writing junk data into the database in regular intervals via cron job Lambda.
The issue has since been addressed by the Debezium team. As of version 1.1, you can configure Debezium to run “heartbeat queries” which rids the need to set up a separate Lambda function. Still, very awkward.
Conclusion
As you can see, our experiences with Debezium were not without issues. When we started off with Debezium, we had a somewhat naive idea in our minds of how much work it would take off of us. While Debezium takes care of the most critical aspects of ETL we absolutely underestimated the amount of elbow grease we would have to put into making it work in our setup. We didn’t think about schema evolution and (de)serialization, we didn’t think about creating boundaries around our database schema and decoupling our system. Then we had issues running it on AWS. Next thing is monitoring: when you’re running a production system you might want to monitor every component of it thoroughly. Debezium runs in the system just like any other microservice and needs to be monitored accordingly. In general, the operations part is not to be underestimated: deployments, version upgrades, setting up alerts, checking dashboards etc…
All things considered, there’s a lot more to it than “spinning it up and let it work its magic” as we had initially thought. There’s a commitment involved when running Debezium and I wish this would have been more clear to us.
Now the question, would I personally use it again? On the one hand, there were times where we suffered great pain: having to announce to the team that our database had run out of space again because the heartbeat Lambda failed to run; failing production deployments because the database schema had changed, triggering an implicit Avro schema evolution and breaking compatibility with a downstream consumer; reworking the database schema over and over to cater to Debezium’s needs; etc. “Debezium broke our system again” has almost become a running gag in our dailies.
On the other hand, Debezium kept its promise of keeping our topics consistent with the database. All faults and failures that we inadvertently caused were ultimately recoverable. Who knows how much time we would have spent chasing consistency bugs if we had chosen the dual writes or SQL polling approach? I don’t even want to think about it. So all in all, yes, I would prefer Debezium over the alternatives any day.